My little identity
Note des éditeurs : Communication du 25 mai 2018 à 9h45. Envoi par courriel aux éditeurs le 26 mai à 23h13.

1. La question de recherche
Alors que la CNIL se demandait en 2017 dans un rapport « Comment permettre à l’homme de garder la main ? » [1] face à l’accroissement des données numériques, ceux qu’on appelle les « Data artistes » tentent de garder la main ou reprendre la main en s’emparant de données de toutes sortes et en les traitant par des algorithmes de leur composition afin de leur donner du sens, ou de révéler leur sens ou de le détourner.
Selon Bruno Bachimont, donner du sens, c’est permettre la projection vers un horizon :
« Donner du sens, c’est (…) échapper à la nécessité d’une réponse immédiate et immanente à l’événement, et inventer un horizon dans lequel cette réponse se construit et se décide. L’événement a du sens pour nous dès lors que nous pouvons le juger d’ailleurs, en fonction d’un horizon qui le comprend, et qui nous permet de nous déterminer ». [2]
Pour que les œuvres, de data art ou de tout autre type, aient du sens, il faut qu’elles adoptent une forme de logique. Et parmi les formes de logique, la narration semble avoir quelque chose en commun avec les données, quand celles-ci sont accessibles sous forme d’un flux en temps réel : ce point commun, c’est la succession d’événements dans le temps. En même temps, l’idée de calcul et d’automatisation semble les rendre incompatibles : comment construire une narration à partir d’une succession automatisée d’événements obéissant à une logique propre ?
S’est donc dès le début de mon travail de thèse posée la question de savoir dans quelle mesure le récit de fiction pouvait s’appuyer sur un flux de données en temps réel – un défi que j’ai décidé de relever par l’expérimentation.
J’avais depuis plus d’un an dans mon petit répertoire d’idées en attente un projet intitulé My little identity. Il portait sur les données de Twitter et sur les actions qui s’y déroulent, qui sont principalement des actions de communication. Comment raconter une histoire à partir de ces actions ? Pour y voir plus clair, je me suis demandée comment apparaîtrait le discours des usagers de Twitter si je le dépouillais de son contenu et que je me focalisais uniquement sur les actes locutoires, c’est à dire sur la manière de communiquer et la stratégie qui est déployée pour cela.
Du fait de la brièveté de ses messages, Twitter favorise l’utilisation de codes très précis pour tisser des relations entre les utilisateurs et entre les contenus (hashtags, mentions, retweets…). Si l’on traduit ces codes d’initiés par leur intention en langage quotidien, qu’obtient-on ? Quelque chose comme :
Machin a dit un truc. Machin a répété ce qu’avait dit Bidule.
J’avais commencé à faire un petit programme de transformation des tweets, puis l’idée en était restée là. En février de cette année, j’ai eu connaissance du travail de Magali Bigey (ELLIADD, Université de Franche-Comté) et de Justine Simon (CREM, Université de Lorraine) sur les discours d’escorte de communication sur Twitter [3]. Elles ont participé à l’ouvrage #INFO Commenter et partager l’actualité sur Twitter et Facebook dans le cadre d’un projet ANR sur la circulation et le partage des informations sur les réseaux sociaux numériques. Cette typologie m’a permis de diversifier le processus de transformation que j’avais imaginé, et le projet a pris ensuite une dimension plastique.
2. My little identity, l’œuvre telle qu’elle sera
L’œuvre à terme se présentera de la manière suivante :
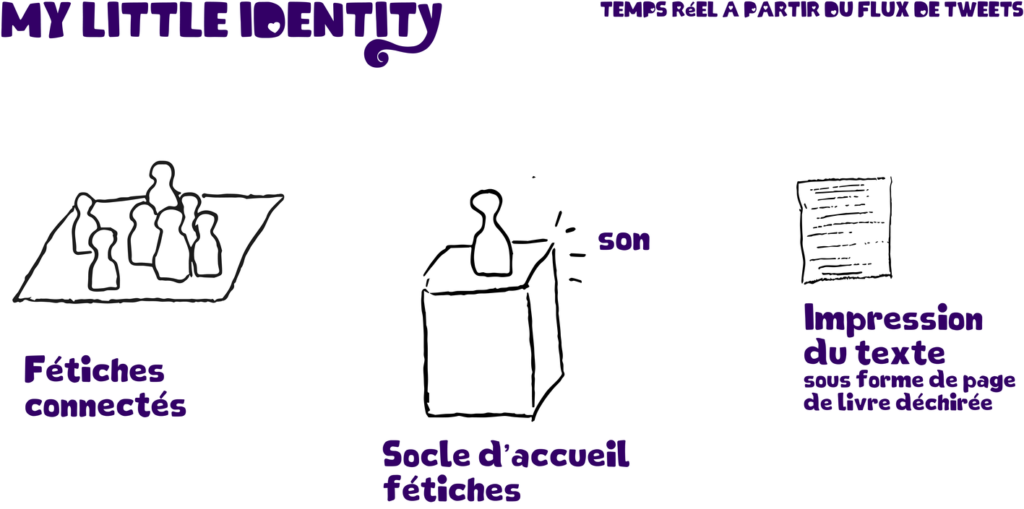
- des figurines de bois, entre fétiches modernes et jouets connectés, incarneront les leaders d’opinion sur Twitter. Le projet vise en effet à tisser des liens entre pratiques ancestrales et comportements modernes, induits par le numérique. Dans l’éco-système des réseaux sociaux numériques et du marketing, ceux qu’on appelle les « influenceurs » bénéficient d’un pouvoir important pour modifier l’opinion de leur communauté, qui compte parfois plusieurs millions de personnes. Chacun à son niveau, les utilisateurs de Twitter tentent de marquer les esprits de leurs followers. Une douzaine de fétiches seront disponibles au départ, choisis parmi les influenceurs les plus populaires en France ou dans le monde. Ces fétiches connectés seront réalisés en impression 3D avec des filaments à base de fibres de bois.
- Les visiteurs pourront positionner le fétiche de leur choix sur un socle. Cela déclenchera l’impression du récit des derniers échanges que cette personne aura eu sur Twitter.
- Chaque fétiche générera également une séquence sonore et musicale qui rendra compte des interactions dans la communication.
- Il sera également possible de générer le propre fétiche du spectateur si celui-ci est utilisateur de Twitter.
Ce dispositif donnera à percevoir les mouvements de ce que nous pourrions appeler « nos petites identités bavardes ».
3. L’interface web
À ce jour, j’ai réalisé seulement une interface web qui permet, à partir d’un nom d’utilisateur de Twitter, d’afficher un texte qui constitue le récit de ses derniers échanges.
Pour choisir les identités qui seront incarnées par les fétiches, je peux choisir les comptes qui ont un très grand nombre d’abonnés ou ceux de personnalités politiques (mais l’inconvénient avec les personnalités politiques c’est qu’elles parlent beaucoup toutes seules pour dire on ne sait quoi). Il existe un outil d’analyse du web à des fins de marketing, Followerwonk, qui propose de classer les utilisateurs de Twitter selon un indice de social authority (indice d’autorité sociale) qui prend en compte les retweets pour calculer un pourcentage d’influence. Donald Trump et ses 53 millions d’abonnés apparaît troisième de ce classement, avec un score de 100 % d’autorité sociale. À l’autre bout du classement, Susan qui habite en Californie n’a que 1% d’autorité sociale. Elle est inscrite depuis 12 ans et n’a que 2 abonnés, mais elle m’intéresse aussi.

4. La typologie des tactiques d’accroche et de mention
Pour construire la programmation, je me suis appuyée sur la typologie des tactiques d’accroche et de mention réalisée par Magali Bigey et Justine Simon. Le projet de recherche Info-RSN a permis de collecter une masse de données extraites des réseaux sociaux numériques faisant mention de liens vers des informations produites par une trentaine de sites d’information.
L’étude de Magali Bigey et Justine Simon portait sur l’information journalistique et le discours d’escorte entourant les liens URL dans Twitter. L’intérêt de ce travail est qu’il se focalisait sur la dynamique de la circulation de l’information, c’est-à-dire sur les stratégies développées pour capter l’attention et inciter à faire circuler l’information. Elles ont travaillé sur deux corpus. Le premier correspond aux 10 000 tweets les plus retweetés durant une période de 6 mois (de mai à octobre 2014). Il leur a permis de dresser une typologie des accroches utilisées. Le second regroupe des tweets générés par les 100 articles les plus partagés sur cette même période (soit un total de 20 000 tweets). Elles l’ont utilisé pour proposer une typologie des usages de l’arobase suivi du nom du compte. Je les cite :
« Les différentes accroches jugées pertinentes dans notre problématique de circulation de l’information se répartissent en deux groupes : celles qui jouent sur un simulacre d’interaction (rubriquage captif, déictiques d’ostension, actes de langage de sociabilité, accroches allocutives, incitations à l’action, accroches délocutives, questions) et celles relevant d’une interaction réelle (mentions). » [4]
À partir de ces deux typologies, j’ai constitué un tableau qui m’a ensuite servi pour concevoir le programme. Pour les mentions, « procédés techno-discursifs relevant d’une volonté d’interaction réelle avec le public visé », j’ai distingué le cas où elles étaient en début de tweet, le cas où elles étaient en fin de tweet et enfin dans toute autre position. Pour chaque cas, j’ai imaginé une transcription narrative. Par exemple, quand la mention figurait en début de tweet j’ai choisi d’écrire « X a interpellé Y » et quand elle figurait en fin de tweet, j’ai écrit « puis X a pris Y a témoin ».
5. Comment ça marche ?
Pour décrire ce type de dispositif, j’ai forgé le concept de moulin à données. Ce concept utilise la métaphore du moulin et de la rivière. Ici la rivière, c’est le flux de tweets. Il est traité par le programme. Il utilise du contenu endogène – les termes présents dans les tweets comme le nom de celui qui écrit et des personnes à qui il s’adresse, ou comme les sujets indiqués par les hashtags – et du contenu exogène – ici les fragments de texte que j’ai écrits et qui s’agencent de façon générative pour donner le flux de l’œuvre.
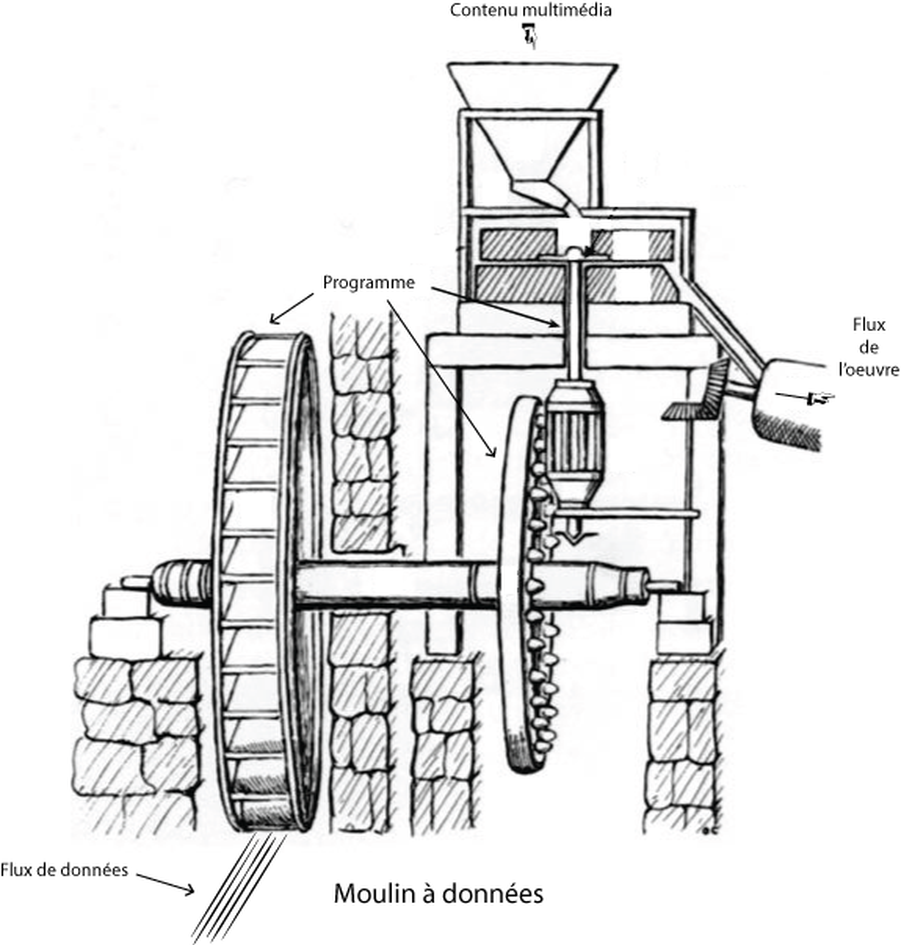
L’API search de Twitter permet (je cite et je traduis) de « renvoyer une collection de tweets pertinents correspondant à une requête spécifiée. Veuillez noter que le service de recherche de Twitter et, par extension, l’API de recherche ne sont pas destinés à être une source exhaustive de Tweets. Tous les Tweets ne seront pas indexés ou mis à disposition via l’interface de recherche ».
L’accès privé n’est pas le mode par défaut de Twitter. Il n’est pas vraiment dans l’esprit de ce service, et son existence est même inconnue de beaucoup d’utilisateurs. Les comptes qui ne sont pas privés sont publics, ce qui implique qu’un tweet est un propos public. Il peut donc être repris et cité.
Je voudrais faire ici une parenthèse sur l’évolution des bases de données. Pendant longtemps, elles ont utilisé le modèle relationnel et se sont appuyées sur différents principes dont celui d’universalité. Dans l’absolu, un système qui répond à ce principe est fait pour gérer toutes les données et tous les besoins qui peuvent se porter sur ces données, ce qui est très pratique pour les artistes qui veulent les détourner. Cependant, à partir de la fin des années 90, la révolution du big data a fait voler en éclats ces principes. Les applications web à très grande échelle n’ont plus les mêmes exigences de cohérence, comme l’expliquent les auteurs du livre Big Data et Machine Learning :
« Pour une entreprise comme Amazon, par exemple, une plate-forme indisponible, ne serait-ce que quelques minutes, n’est pas envisageable car elle causerait la perte de dizaines de milliers de commandes. Priorité absolue est donc donnée aux performances et à la disponibilité. Celles-ci sont assurées aujourd’hui par la mise en œuvre d’architectures distribuées sur des centaines voire des milliers de machines. Dans un tel contexte, parvenir à une parfaite intégrité des données et une stricte isolation des transactions est extrêmement difficile et coûteux. (…) De manière plus significative encore, l’ancienne exigence de cohérence des données ne correspond souvent plus aux priorités du business. Qui se soucie vraiment que la liste des commentaires d’un post sur un réseau social soit vue de la même manière au même instant par tous les utilisateurs ? » [5]
Cette évolution amène à devoir gérer les incohérences, comme les cas de surbooking ou de commandes indisponibles, de manière manuelle par des procédures à l’amiable moins coûteuses. Les API mises à disposition des développeurs par ces entreprises sont du coup moins fiables que celles qui sont issues de systèmes de gestion de bases de données de type relationnel. Ainsi l’API de recherche de Twitter (Search API) n’est pas exhaustive, elle ne donne accès qu’à un échantillon des tweets publiés durant les sept derniers jours.
Face à l’accroissement de la rigidité du modèle de données, les artistes doivent s’accommoder des limitations des bases de données disponibles ou trouver des parades afin de les contourner, en utilisant par exemple le scraping, technique d’acquisition de données directement à partir du web.
Dans My little identity, je n’ai pas eu à utiliser cette technique, le programme se connecte de manière officielle à l’interface de programmation fournie par Twitter pour faire des recherches sur les tweets ; mais il est important de savoir que cette recherche n’est pas exhaustive. On voit bien que la tension entre le politique et l’économique est présente en permanence lorsqu’il s’agit de l’utilisation des données.
Le premier geste du « data artist » est d’analyser sa source et de se positionner par rapport elle : dans tous les cas, il la détourne et il l’utilise comme énergie cinétique, mais il peut la servir ou au contraire la questionner. Les choix techniques du producteur de données (puis de l’artiste) sont dépendants de cette tension. La finalité de la production des données joue également un rôle majeur dans la façon dont les données seront sélectionnées et structurées. Le social et le technique (qui n’est jamais neutre) sont intimement liés.
Face à une œuvre de type « moulin à données » il est donc primordial de se poser les questions suivantes :
- Qui produit les données sources ? Dans quel but ?
- Le producteur des données et l’acteur de l’événement consigné sous forme de données appartiennent-ils à la même entité ? Sinon, de quel type sont leurs relations ?
Avant même d’aborder la programmation et le choix de l’interface, le travail opéré par l’artiste sur les données se révèle très signifiant. C’est le premier lieu de la création de sens qui s’opère dans les moulins à données, il ne faut pas le négliger.
Ici je lance une requête avec un nom d’utilisateur et je récupère le contenu d’une sélection de 20 tweets parmi les derniers émis par cet utilisateur.
6. Un récit ?
Si on se souvient de ma question de recherche :
Dans quelle mesure le récit de fiction peut- il s’appuyer sur un flux de données en temps réel ?
on pensera que je me suis éloignée de cette question avec ces expérimentations sur Twitter. Pourtant il s’agit bien de fiction, et même de récit.
Utilisons le schème interactif élaboré par Bertrand Gervais en 1990 pour vérifier si les éléments indispensables à la pré-compréhension de l’action sont bien présents.
- Le cadre temporel est établi, le récit se déroule au passé puisqu’il raconte 20 des derniers tweets.
- Le cadre spatial est indistinct, tout cela se déroule sur Twitter, donc dans le cyberespace. Mais s’il y a une métaphore dans My little identity, elle est peut être là : l’expression du récit du discours laisse croire que ces actions ont eu lieu en présence des personnes, dans un espace matériel. Les corps réapparaissent car l’écrit est transformé en parole. Ce n’est pas X a écrit mais X a dit qui s’affiche.
- L’agent de l’action, c’est celui qui tweet, l’influenceur en puissance. L’opération est l’action communiquer.
- Mais quelle est l’intention ?
En gommant le contenu des tweets et en se focalisant sur les actes locutoires, My little identity efface volontairement l’intention, ne laissant apparaître que la volonté d’être écouté, la volonté de capter l’attention, une intention qui semble dérisoire lorsqu’il ne reste plus qu’elle.
On sent bien que tout cela ne mène à rien, n’aboutira à rien, que cette histoire n’aura pas de fin, que les personnages continueront à s’agiter indéfiniment sans qu’un quelconque dénouement ne survienne. Et c’est sans doute là que se trouve l’intérêt de ce dispositif.
Je voudrais conclure avec un questionnement sur l’ironie : il me semble qu’il y a de l’ironie dans ce dispositif, mais qu’elle réside davantage dans le processus que dans les mots eux-mêmes.
Le nom My little identity (Ma petite identité) s’est imposé à moi très tôt par analogie avec My little pony, Mon petit poney. Il s’agit d’une marque de jouets, en forme de poney, avec des cheveux multicolores pouvant être coiffés, qui ont été commercialisés à partir des années 80 et autour desquels de nombreux produits dérivés ont été diffusés. Pourquoi faire un rapprochement entre ces jouets et ce travail sur Twitter ? Parce que ce dessin animé est l’objet d’un véritable culte dans la culture geek. Il compte des dizaines de milliers de fans à travers le monde. La plupart sont des jeunes hommes entre 14 et 40 ans, hétérosexuels ; on les appelle « bronies », brothers of ponies. Dans Mon petit poney, ils apprécient la variété des niveaux de lecture (nombreuses références pour adultes). Ils apprécient également le message d’amour et de tolérance qu’on trouve dans le dessin animé et s’insurgent contre le cynisme habituel – dans le sillage de la « nouvelle sincérité ».
Selon Harvie Ferguson, chercheur en sociologie, le 11 septembre aurait marqué la fin de l’âge de l’ironie et le début de l’âge de la « nouvelle sincérité ». Dans son article Le glamour et la fin de l’ironie, il écrit (je traduis) :
« Le glamour est une non-identité non-ironique – une brillance de surface, qui, en fait, ne cache ni ne révèle la « personne » ». [6]
Ce mouvement pose comme postulat qu’il serait possible de lever toute ambiguïté dans la communication et évacuer la question de l’interprétant. Comment se place My little identity par rapport à cette question ? Mon intention de départ n’était pas ironique, mais je pense que c’est le processus même de soustraction, de la limitation aux actes locutoires qui produit du comique ou du poétique. Gustavo Gomez-Mejia cite dans sa communication Tomachevski : « La parodie est un agent de dés-automatisation ». Or ici, au contraire, c’est le fait de révéler l’automatisation du discours qui produit la parodie. Peut-être est-ce qu’apparaît ici l’envers du « rien » dont parlait Arnaud Maïsetti ? Et pour retrouver la thématique d’une matinée du colloque, peut-être est-ce réduire les échanges sur Twitter à leurs didascalies énonciatives et énonciatrices ?
Au final, tout cela n’est peut-être, pour reprendre les mots d’Anaïs Guilet, qu’une « blague crypto-sophistiquée ».

http://www.francoise-chambefort.com/my-little-identity
Notes
[1] Commission Nationale de l’Informatique et des Libertés, Comment permettre à l’Homme de garder la main ? Rapport sur les enjeux éthiques des algorithmes et de l’intelligence artificielle, S.l., CNIL, 2017.
[2] Bachimont Bruno, Le sens de la technique : le numérique et le calcul, S.l., Encres Marines/Les Belles Lettres, 2010, p. 28-29.
[3] Magali Bigey, Justine Simon, « Analyse des discours d’escorte de communication sur Twitter : essai de typologie des tactiques d’accroches et de mentions », dans Arnaud Mercier, et Nathalie Pignard-Cheyel (éd.), #info : Commenter et partager l’actualité sur Twitter et Facebook, Paris, Éditions de la Maison des sciences de l’homme. Le (bien) commun, 2017 p. 55‑86.
[4] Magali Bigey, Justine Simon, « Analyse des discours d’escorte de communication sur Twitter : essai de typologie des tactiques d’accroches et de mentions », dans Arnaud Mercier, et Nathalie Pignard-Cheyel (éd.), #info : Commenter et partager l’actualité sur Twitter et Facebook, Paris, Éditions de la Maison des sciences de l’homme. Le (bien) commun, 2017, p.61.
[5] Pirmin Lemberger, Marc Batty, Médéric Morel, Jean-Luc Raffaëlli, Big Data et Machine Learning – Manuel du data scientist, 2e éd. S.l., Dunod, 2016, p. 34.
[6] Harvie Ferguson, « Glamour and the end of irony », The Hedgehog Review, 1, n° 1, 1999.