The Two Webs
Note des éditeurs : Communication du 23 mai 2018 à 10h00. Envoi par courriel aux éditeurs le 18 juin à 10h37.
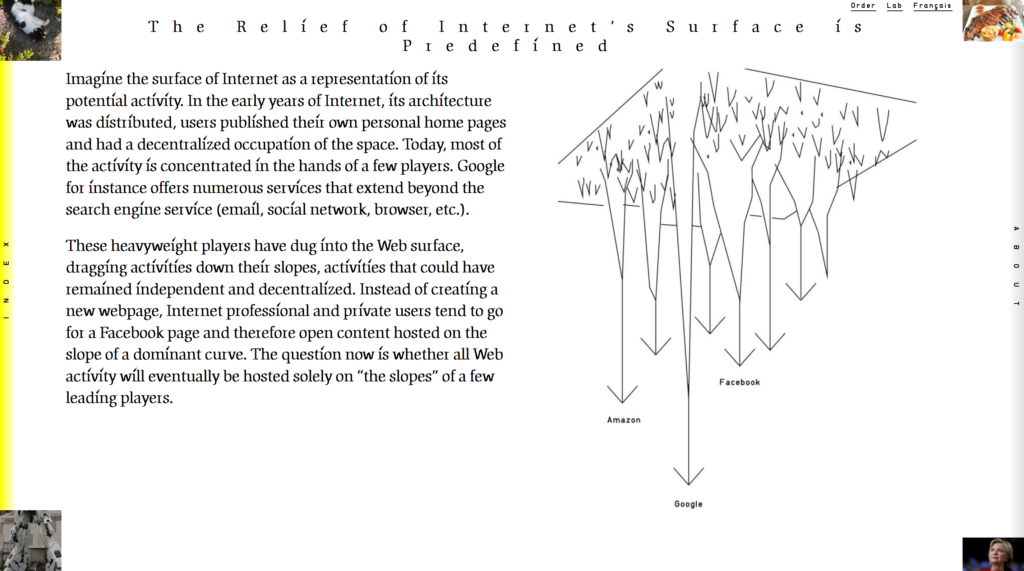
« Envisageons Internet comme une surface dont l’étendue représenterait son activité potentielle. À la naissance d’Internet, son architecture était distribuée, les utilisateurs publiaient des pages personnelles sur le web et occupaient l’espace de manière décentralisée. Aujourd’hui, certains acteurs concentrent la majorité de l’activité : Google par exemple propose de nombreux services différents qui s’étendent au delà du moteur de recherche (mail, réseau social, navigateur, etc.).
Ces acteurs, ayant un poids plus fort, ont creusé la surface du web entrainant sur leur pente un ensemble d’activités qui auraient pu rester indépendantes et décentralisées. Les internautes, professionnels ou particuliers, au lieu d’ouvrir une page web vont plus naturellement se tourner vers une page Facebook et ainsi ouvrir du contenu hébergé sur le dénivelé d’un fossé dominant. On peut se demander si un jour le web entier se retrouvera uniquement sur la pente de certains grands acteurs. »
Louise Drulhe, Atlas Critique d’Internet, 2015
Prolonger une hypothèse
The Two Webs est le résultat d’un travail de recherche développé dans le cadre de ma résidence à Lafayette Plug and Play avec le soutien de la fondation Lafayette Anticipation de septembre 2016 à juin 2017.
Ce projet vient de la volonté de poursuivre le travail initié dans l’un des quinze chapitres de L’Atlas Critique d’Internet : Internet a un relief dirigé. Dans cette hypothèse de travail, je proposais une représentation de l’espace d’Internet en cartographiant son relief. Dans l’Atlas, j’utilisais comme donnée le classement des sites web selon Alexa. Si la première carte fonctionnait comme un croquis, mon nouvel objectif était de développer le modèle exact.
Création de base de données et choix des données
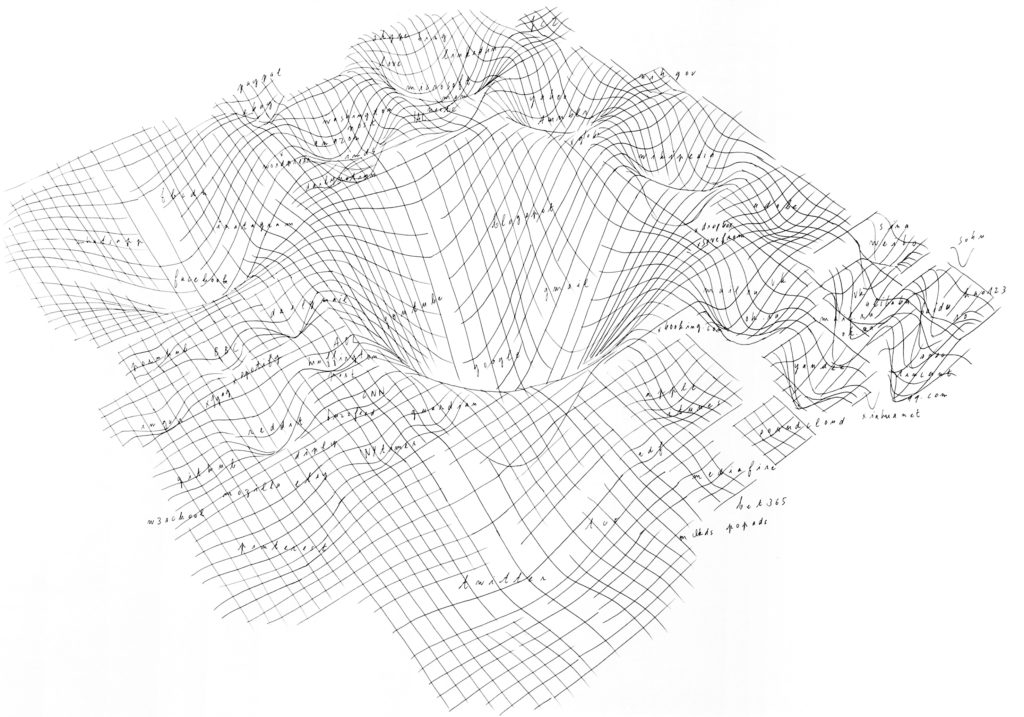
Le traitement des données est le résultat de trois étapes. La première a été de s’assurer de la fiabilité d’une base de données malgré des informations contradictoires. J’ai compris à travers mes recherches que le site Alexa (produit par Amazon) était utilisé comme référence dans le domaine universitaire. Je l’ai donc utilisé comme base de comparaison pour les autres informations trouvées. Ensuite, il n’existe pas de base de données qui regroupe les sites Web en fonction de leur propriétaire. La deuxième étape a été de créer manuellement cette base de données originale ; elle m’a servi de matrice pour définir la taille de chaque groupe. La dernière étape a été de définir quel jeu de données je souhaitais utiliser. J’ai produit une série de coupes d’Internet pour regarder ce qui me paraissait le plus juste, en terme de représentation.
Profondeur / Largeur / Proximité
La carte s’appuie sur un trio de données. La profondeur est définie par le nombre de visites par jour (Wolfram). La largeur d’un trou est définie par le nombre de liens entrants, cette donnée exprime la popularité d’un site ou la visibilité comme défini par Tim Bray (Measuring the Web, 1995). Enfin la répartition des gouffres dans l’espace, leur positionnement est défini par l’upstream, c’est-à-dire, quels sites ont été visités juste avant un site donné.
Le croisement de ces données me permet d’avoir une carte du web plus pertinente que si j’utilisais uniquement les données de trafic. Par exemple, les sites chinois, comme Baidu, sont très étroits. C’est-à-dire qu’ils ont beaucoup de visites, mais peu de liens entrants. La Chine étant un pays très peuplé, et le nombre de sites Internet étant restreint en raison de la censure, les données de trafic sont démesurées. Si les sites chinois sont très visités, ils n’ont en revanche pas beaucoup de liens externes, car ils sont mal connectés avec le reste du réseau mondial. À l’opposé, bien que Twitter ait un nombre de visiteurs équivalant à Baidu, il possède énormément de liens entrants, ce qui lui confère une forme plutôt plate, ouverte et peu profonde. Ainsi, sur la carte du réseau mondial, Twitter ressort par rapport aux sites chinois, ce qui est cohérent étant donné que historiquement Twitter s’est imposé comme un service majeur. D’autres acteurs comme Facebook ou Google, eux, cumulent les deux, beaucoup de visites et beaucoup de liens entrants, ce qui leur donne une forme homogène. Cette représentation peut faire écho à l’évolution des montagnes. Les montagnes jeunes étant pointues et hautes, tandis que les montages anciennes prennent avec le temps la forme de collines.
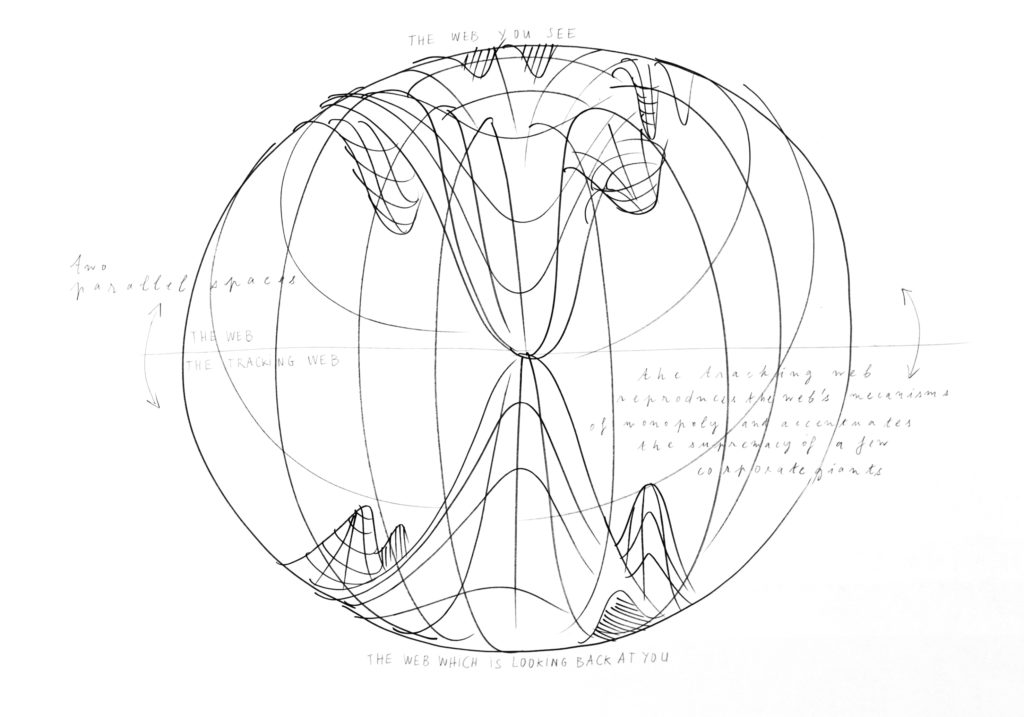
« There is one web users see in their browsers, but there is a much larger hidden web that is looking back at them ».
Tim Libert, « Exposing the Hidden Web: An Analysis of Third- Party HTTP Requests on 1 Million Websites »,International Journal of Communication, 9, (2015), 3544–3561.
Un espace caché
Le chercheur américain Tim Libert et son équipe ont défini l’existence d’un web caché : des pages web conçues uniquement pour récupérer les métadonnées des internautes. Ses recherches sont présentées sous la forme de plusieurs articles, où il présente les résultats qu’il a obtenus grâce au développement d’un outil, webXtray. Ce robot analyse l’activité extérieure de tracking (bénigne ou non) sur les 1 million de premiers sites.
Il explique que 90 % des sites Internet font fuiter nos données, consciemment ou non. En moyenne, lorsque nous consultons un site Internet, il y a neuf pages qui sont présentes mais cachées et qui envoient des requêtes à notre page pour récupérer nos données. Google a la capacité de recevoir nos données depuis 80 % des sites Internet dans le monde. Il passe entre autres par son service gratuit installé sur la plupart des sites Internet : « Google Analytics ». Sur ma représentation des principaux sites Internet du monde, les seuls sites à ne pas envoyer de données à Google sont Wikipedia et certains sites chinois. Le seul site à grande échelle à ne fuiter aucune donnée est Wikipedia. Si Wikipedia n’a aucun mouchard, c’est parce qu’ils ont fait un choix éthique et qu’ils se prémunissent de toute intrusion involontaire de la part de Google, Facebook ou autre.
Le plug-in Ghostery à installer sur un navigateur permet de connaitre le nombre de mouchards sur chaque site. L’usage de Ghostery est néanmoins controversé ; certains pensent qu’il pourrait lui aussi utiliser les données des internautes.
Cartographie des deux webs
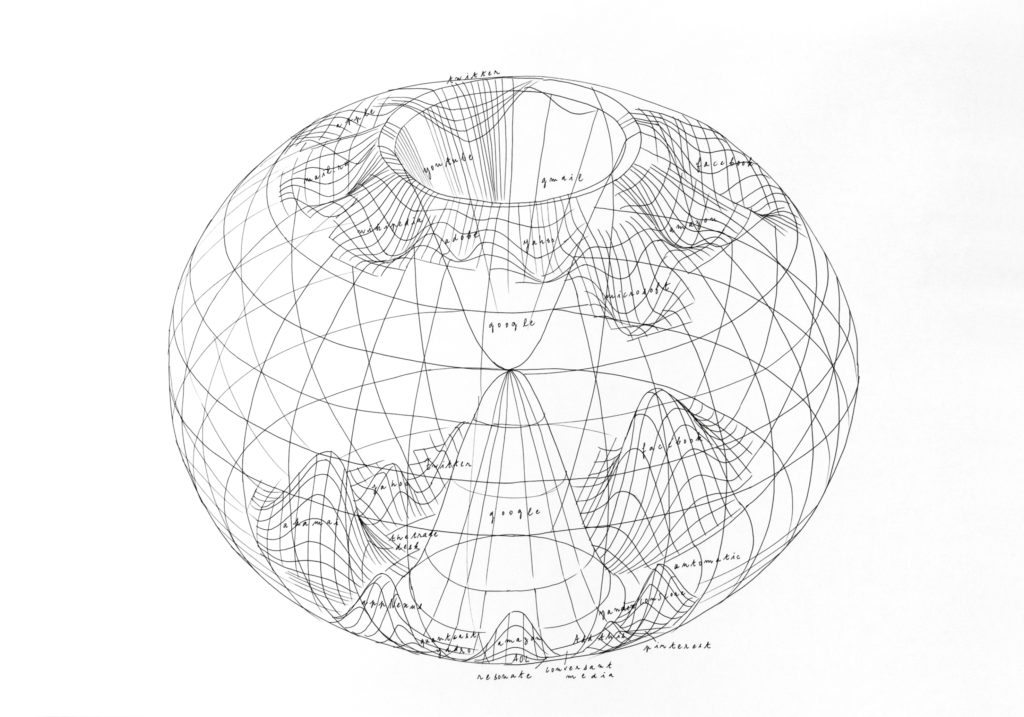
À trois niveaux, j’ai observé une symétrie entre le web classique et le tracking web. La première ressemblance est l’existence de monopoles dans les deux espaces. La majorité de l’activité du web est concentrée entre quelques groupes. Et les données générées par l’ensemble de l’humanité connectée sont récoltées par quelques dizaines d’acteurs. Le mimétisme entre les deux espaces est renforcé dans la mesure où ce sont les mêmes acteurs (Google, Facebook, Amazon, Twitter, Microsoft…) qui détiennent les deux pôles ; à l’exception de quelques inconnus du web classique, comme Akamai par exemple. L’étape finale était d’analyser comment Google occupait exactement la même position dans les deux situations : une position largement prédominante. Les rapports de proportion entre Google et les acteurs qui l’entourent sont similaires dans les deux webs.
L’objectif de mon travail était de montrer cette symétrie des monopoles en regard avec mon travail précédent. Le tracking web se définit comme la contre-forme du web. Par un effet miroir, il est le double du web, sa forme complémentaire. Dans les représentations du web classique seul, l’espace semble inachevé, « coupé brute ». La cartographie de ces deux espaces forme une sphère, un écosystème uni où le ruissellement des données d’un espace à l’autre crée un cycle de vie. Cette forme rappelle aussi la formation des stalagmites à partir de l’égouttement des stalactites.
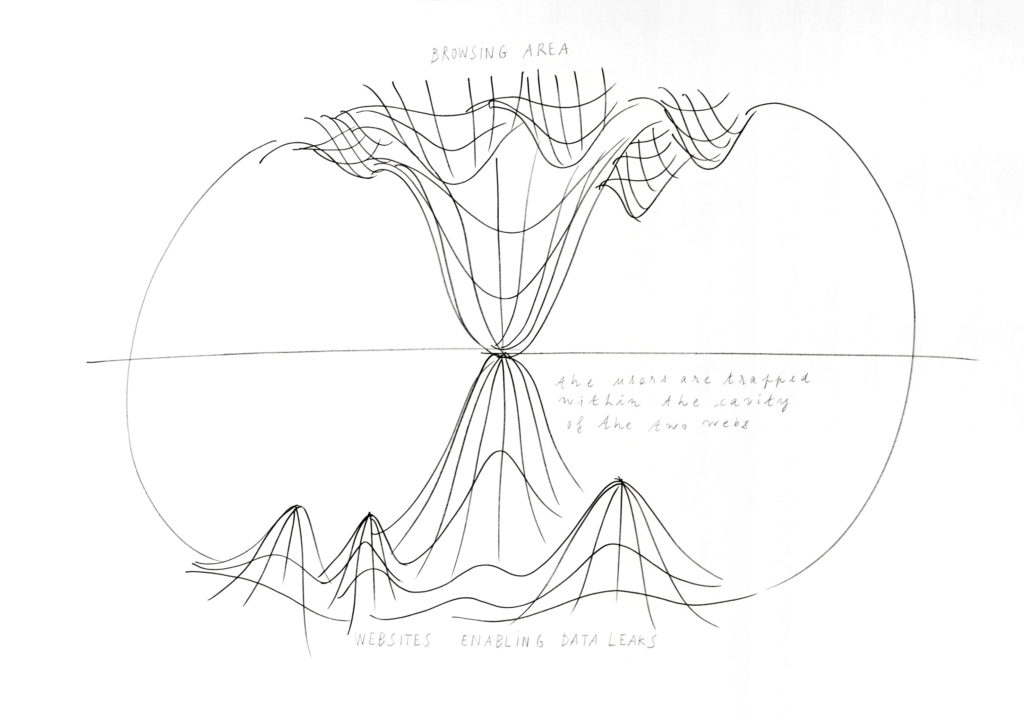
Cet enchaînement spatial m’a permis de mettre à jour la position particulière de Google que j’avais déjà essayé de dessiner. Par mon processus de miroir je faisais ressortir une nouvelle forme : le double gouffre de Google, qui dessine une figure à l’intérieur du web, un « sablier », qui transperce le globe de l’internet. Cette révélation spatiale était le résultat d’un processus de recherche et non une volonté formelle. Ce sont les données utilisées et les étapes de travail qui m’ont permis d’aboutir à cette modélisation du web. Cette carte des deux webs permet de comprendre la position de Google.